TL;DR: You can help develop better quantum decoders by playing the Erratiq game.

Human perception allows us to automatically detect patterns. This evolutionary trait has been crucial for our survival, enabling us to recognize faces, navigate environments, and make sense of complex data. For centuries, detecting repeatable patterns and understanding the actions needed to affect them has been the cornerstone not only of survival, but of scientific discovery and technological advancement. Think of the citizen scientists in the Foldit project, whose spatial reasoning and human intuition allowed them to solve complex protein-folding structures that had stumped automated algorithms for years. What if we could employ this exact same ability to improve the performance of quantum error correction?
In principle, quantum error correction allows us to sustain meaningful computation on a quantum computer well beyond the physical limits imposed by the environment. It effectively stabilizes the fragile quantum state. When combined with fault-tolerant operations, it can unlock the full potential of quantum computing—bringing significant implications for cryptography, optimization, chemistry, and the simulation of complex quantum systems. This stabilization is made possible by building a certain redundancy into the encoding of quantum information, which allows us to detect and correct (or at least track) physical errors.
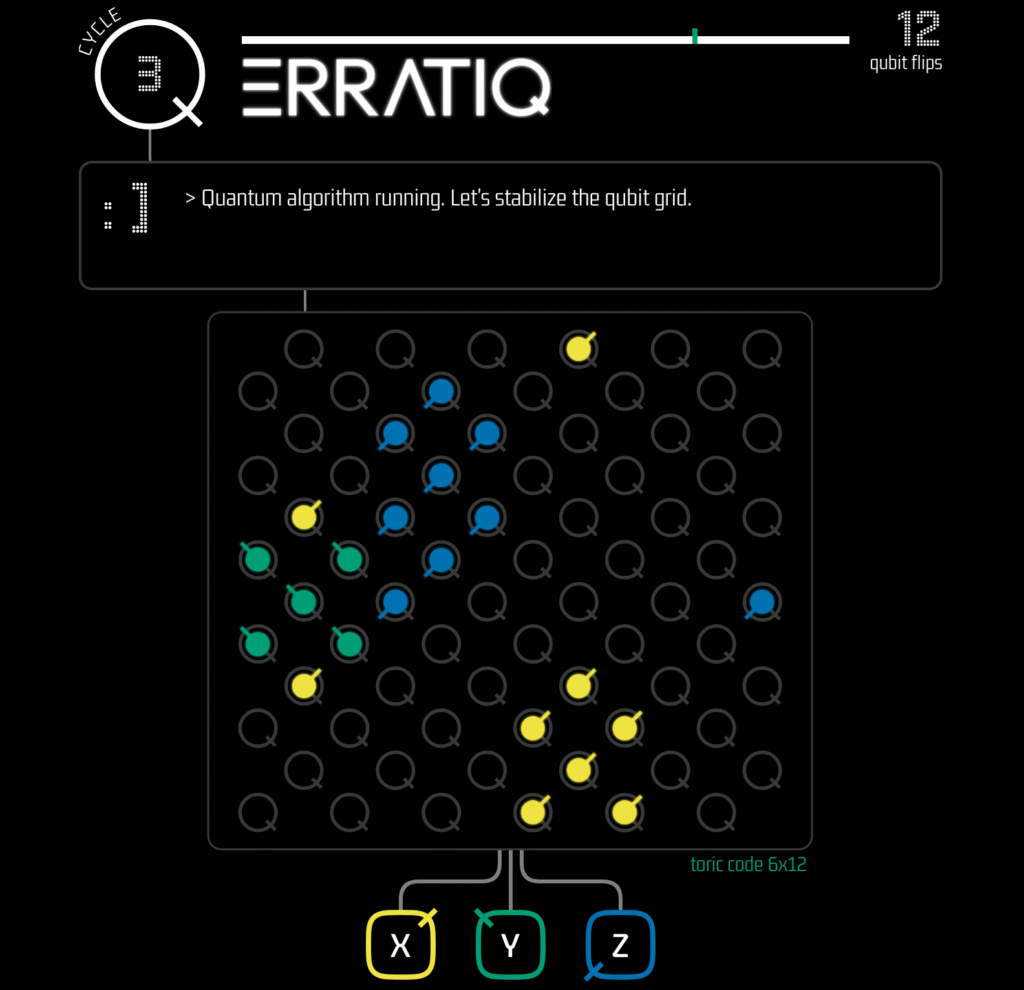
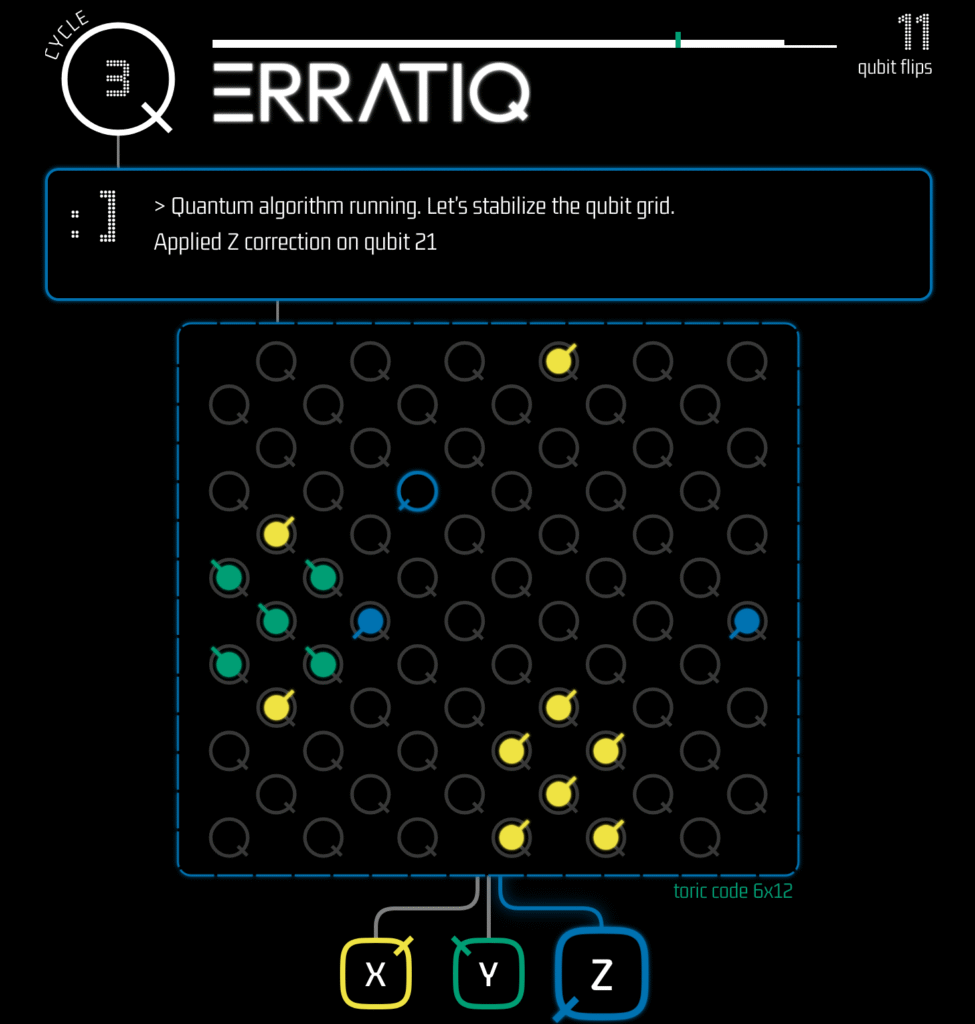
However, none of this works without a decoder—a classical algorithm that converts the information from the sensors (syndromes) into a correction operation. While many decoders have been proposed, including minimum weight perfect matching, belief propagation, and machine learning-based approaches, they often struggle with scalability and real-time performance, especially as the size of quantum systems increases.
Recently, machine learning (ML) based decoders have shown immense promise. But they often require massive amounts of training data and computational resources, which can limit their practicality. For instance, a reinforcement learning (RL) agent starts with no prior knowledge of the system and must learn to make decisions solely based on feedback from its environment. As an illustrative example, consider an RL agent trained to decode a surface code of distance-15. The action space of the agent is astronomical, preventing any meaningful training without significant simplifications. And even with a simplified action space, the agent requires a massive number of training episodes to learn an effective decoding strategy, which is exceptionally time-consuming and computationally expensive.
Why not ask a human for help?
That is the idea behind Erratiq, a game designed in collaboration between Leiden University and Waag Futurelab to harvest the potential of the human mind to guide the training of ML-based decoders for quantum error correction. By engaging players in a fun and interactive way, Erratiq aims to collect valuable data on how humans approach the problem of decoding quantum errors. This data can then be used to train more efficient and effective machine learning models.
The game is built to be accessible to a wide audience, regardless of their background in quantum computing, providing a platform for players to directly contribute to the advancement of quantum error correction research. In its first version, it already features a 72-qubit toric code and a 30-qubit LDPC code. The latter, in particular, represents a family of resource-efficient but hard-to-decode quantum error-correcting codes, making it an ideal candidate for testing how well human intuition can guide ML training.
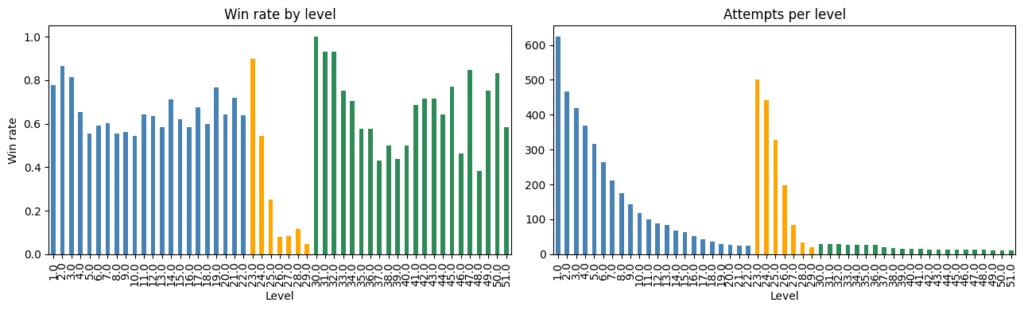
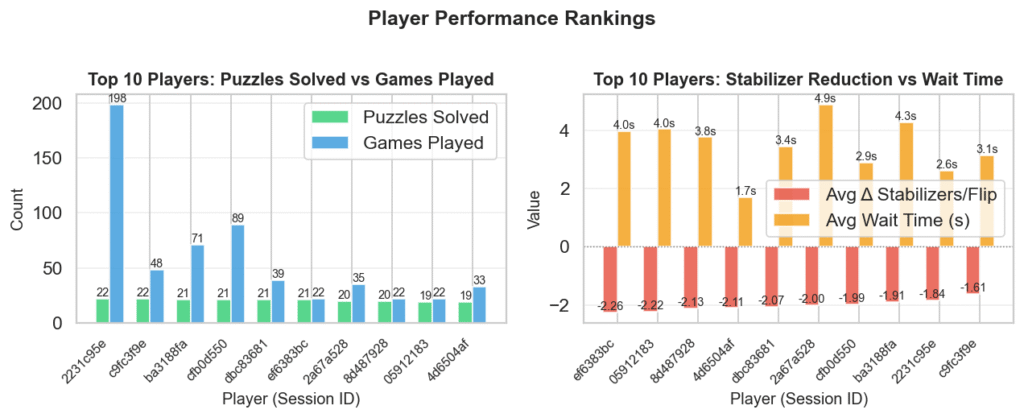
So far, we have analyzed about 5,500 games and found that some players can already decode errors at a level comparable to state-of-the-art machine learning decoders, achieving a reduction in stabilizers per flip to below 2. However, to truly train a robust machine learning model, we need to collect a massive amount of data, and we are still in the early stages of this process.
This is where we need your help! By playing Erratiq, you can contribute to the advancement of quantum error correction research and help us unlock the full potential of quantum computing. Whether you are a seasoned gamer or just looking for a fun way to contribute to science, Erratiq offers an engaging and rewarding experience. So why not give it a try and see how your intuition can help shape the future of quantum computing?
What will we do next? The dataset we collect will serve two main purposes:
- As a prior for a reinforcement-learning agent, seeding the policy search with human-derived trajectories.
- As a training corpus for a decision-transformer model that will replicate human move sequences and produce an interpretable account of human decoding strategies.
Next time, I will dive into the idea behind the decision transformer and show exactly how it can be used to train a machine learning model that replicates human decoding strategies for quantum error correction.