
GitHub repo: https://github.com/jan-a-krzywda/marl-f1
“What I cannot create, I do not understand.” When Richard Feynman wrote those famous last words on his blackboard, he probably didn’t have Multi-Agent Reinforcement Learning (MARL) for Formula 1 strategy in mind. Nevertheless, the thread that connects his philosophy to modern motorsport is the power of model-based thinking.

To prove this point, this post will attempt to model the new 2026 Formula 1 regulations [1], which push the sport in a vastly more complex direction. With the highly anticipated season kicking off this weekend in Australia, everyone is wondering how the new rules will affect racing at 300 km/h in this state-of-the-art engineering endeavor. Since nobody knows for sure, we are going to build it to find out.

I argue that the new regulations have fundamentally transformed F1 into a complex, sequential decision-making problem—the exact type of puzzle natively solved by reinforcement learning (RL). In an RL framework, an agent operates within an environment, takes actions, receives rewards, and learns increasingly clever strategies over time. This shift was recently recognized by the Mercedes-AMG team, who published a pre-print on optimizing race strategy using RL [2]. However, while they successfully beat their baseline, I believe they missed a massive opportunity by ignoring the multi-agent aspect of the sport. At the end of the day, a race strategy is only as good as how it stacks up against the reactive, evolving strategies of your opponents.
But why sequential decision making?
In the 2026 era, the driver essentially becomes a battery manager, as roughly 50% of the car’s power is now provided by the electric motor. Drivers must constantly decide how to deploy electrical energy during the race—for instance, sacrificing pace on one lap to harvest energy, allowing them to unleash a massive power advantage later to execute an overtake. Combine this with standard F1 strategic decisions, like pit stops and tyre compounds, and the tactical options become combinatorially heavy.
I will try to prove that even a simple model of this environment can be used to understand the emergent behavior of drivers and teams under these new rules. We will frame this as a Markov Decision Process (MDP), assuming the driver blindly follows the suggestions of the Pit Wall, which has access to the current state of the car and the track.
In an MDP, the team makes decisions based solely on the current state of the environment, not on the entire history of the race. With 11 teams on the grid, this is the perfect setup for a Multi-Agent Reinforcement Learning (MARL) problem—a branch of machine learning where multiple agents learn to make decisions in a shared environment. In our case, the agents are the Pit Walls, and the environment is the race itself. The agents learn to adapt to each other and improve their performance by observing the consequences of their decisions (rewards). But before we can train them, let’s build the simulation.
1. The Agents: You Are The Pit Wall
In F1, the cars don’t make the long-term strategic decisions; the teams do. Therefore, our MARL agents aren’t the 22 individual cars. Instead, we have 11 Team Agents (including the newly approved Cadillac F1 team). Each agent controls two cars simultaneously, forcing the AI to learn real-world constructor tactics like split strategies and using a “wingman”.
Preventing AI Overfitting with a Randomized Grid
If we start the Red Bull (BlueCow) agent (“Du du du du”) on pole position in every single training episode, the neural network will never learn how to fight through traffic. To build a robust Reinforcement Learning environment, we will shuffle the drivers into a random grid order at the start of every race. We do this inside the standard Gymnasium reset() method, guaranteeing that the agents face a brand new puzzle every time the lights go out. Also to keep the FIA lawyers happy while keeping the grid recognizable, we initialize our environment with some legally distinct spoof names.
import numpy as np
import random
import time
import os
class F1TeamEnv:
def __init__(self, total_laps=25):
# The 11-team, 22-driver spoof grid
self.driver_map = {
self.driver_map = {
"BlueCow": [("VER", "Max Versplatton"), ("LAW", "Liam Awesome")],
"Merciless": [("RUS", "Forge Hustle"), ("ANT", "Kimi Macaroni")],
"Furrari": [("LEC", "Chuck LeClutch"), ("HAM", "Louis Hamstring")],
"McPapaya": [("NOR", "Lando Chuckris"), ("PIA", "Osco Pastry")],
"Astonishing": [("ALO", "Nando Alfonso"), ("STR", "Lance Scroll")],
"Alpain": [("GAS", "Peter Ghastly"), ("COL", "Franky Colapunch")],
"Billiams": [("ALB", "Alex Album"), ("SAI", "Carlos Signs")],
"ToroLoco": [("HAD", "Isaac Badger"), ("LIN", "Artie Lindblad")],
"Sober": [("HUL", "Nico Bulkensmear"),("BOR", "Gabe Tortellini")],
"Hassle": [("OCO", "Esteban Acorn"), ("BEA", "Ollie Birdman")],
"CaddyShack": [("PER", "Surge Perez"), ("BOT", "Battery Voltas")]
}
self.teams = list(self.driver_map.keys())
self.total_laps = total_laps
self.reset() # Initialize the first race
def reset(self, seed=None):
"""Called at the start of EVERY new training episode to randomize the grid."""
if seed is not None:
random.seed(seed)
np.random.seed(seed)
self.current_lap = 0
all_drivers = []
for team_name in self.teams:
for driver_idx in [0, 1]:
drv_code, drv_name = self.driver_map[team_name][driver_idx]
all_drivers.append({"id": drv_code, "full_name": drv_name, "team": team_name})
# Shuffle the grid!
random.shuffle(all_drivers)
self.cars = []
for grid_pos, driver_data in enumerate(all_drivers):
driver_data.update({
"total_race_time": grid_pos * 1.5, # 1.5s gap per grid slot
"tyre_compound": 2, # Start on Mediums
"tyre_age": 0.0,
"battery": 1.0,
"pit_stops": 0,
"last_lap_time": 0.0,
"status": "GRID",
"current_pace_cmd": 1
})
self.cars.append(driver_data)
I want to highlight that the parameters defined above are relevant for the logic, and there should be not considered as an agent “state” in the RL sense – i.e. set of parameters that are used to perform an action. Those will be defined below.
2. Defining the RL Architecture: States and Actions
To hook our Python engine up to a neural network, we need to rigorously define what the agents can do (Action Space) and what they can see (Observation Space). This is exactly where the game theory of F1 shines—teams have perfect information about their own cars, but incomplete (public) information about their opponents.
The Action Space
Each Pit Wall agent controls two cars. Every lap, the agent outputs a joint action vector containing four discrete choices: [Car_1_Pace, Car_1_Pit, Car_2_Pace, Car_2_Pit].
- Pace (0, 1, 2) : Harvest (Save Battery), Maintain, or Push (Deploy Battery).
- Pit (0, 1, 2, 3) : Stay Out, Pit for Softs, Pit for Mediums, Pit for Hards.
The Observation Space (Public vs. Private Data)
We structure this as a Gymnasium Dict space. Every time the simulation steps forward, the environment feeds the agent a dictionary containing:
1. Global & Public State (Visible to everyone):
lap_fraction: Percentage of the race completed.competitor_gaps: The time deltas (intervals) to the cars immediately ahead and behind.competitor_tyres: The current tyre compound and estimated tyre age of surrounding cars.
2. Private State (Visible only to the specific Team Agent):
battery_charge: The exact state of charge of the MGU-K. Opponents do not know if you have the battery to defend against an undercut!override_unlocked: A boolean indicating if the car successfully crossed the detection line within 1 second of the car ahead.
from gymnasium.spaces import MultiDiscrete, Box, Dict, Discrete
# 1. THE ACTION SPACE
self.action_spaces = {
agent: MultiDiscrete([3, 4, 3, 4]) for agent in self.teams
}
# 2. THE OBSERVATION SPACE
self.observation_spaces = {
agent: Dict({
# Global & Public Data
"lap_fraction": Box(low=0.0, high=1.0, shape=(1,), dtype=np.float32),
"gap_ahead_c1": Box(low=0.0, high=100.0, shape=(1,), dtype=np.float32),
"gap_behind_c1": Box(low=0.0, high=100.0, shape=(1,), dtype=np.float32),
"opp_tyre_c1": Discrete(4),
# Private Telemetry (Car 1)
"c1_tyre_compound": Discrete(4),
"c1_tyre_age": Box(low=0.0, high=100.0, shape=(1,), dtype=np.float32),
"c1_battery": Box(low=0.0, high=1.0, shape=(1,), dtype=np.float32),
"c1_override_unlocked": Discrete(2),
# Private Telemetry (Car 2 follows the same structure...)
}) for agent in self.teams
}
3. The 2026 Rules: The Death of DRS & The Birth of “Override”
The biggest change in the 2026 regulations is the removal of the traditional DRS overtaking aid. It is replaced by Manual Active Aero (Corner/Z-Mode and Straight/X-Mode) and the MGU-K Overtake Mode (Override). If a chasing car is less than one second behind the car ahead at the detection line, they are allowed to deploy a massive electrical energy spike (350kW all the way up to 337 km/h) without the standard high-speed taper. In our code, agents can choose to “Push”, but the simulation dictates whether they get a standard “Boost” (BST) or the massive “Overtake” (OVR) based on their track position.
We handle this, along with exponential tyre degradation, tire-depedent pace difference and battery management in a clean helper function:
def _process_car_lap(self, car, team_action):
"""Handles pit stops, energy deployment, tyre wear, and raw lap time calculation."""
base_lap_time = 85.0
pit_loss_time = 22.0
# Decode actions
is_car_2 = (car["id"] == self.driver_map[car["team"]][1][0])
pace_cmd = team_action[2] if is_car_2 else team_action[0]
pit_cmd = team_action[3] if is_car_2 else team_action[1]
car["status"] = "OUT"
car["current_pace_cmd"] = pace_cmd
# 1. Pit Stop Logic
if pit_cmd > 0:
car["total_race_time"] += pit_loss_time
car["tyre_compound"] = pit_cmd
car["tyre_age"] = 0
car["pit_stops"] += 1
car["status"] = "PIT"
# 2. Energy/Aero Logic (Harvest, Boost, Override)
pace_modifier = 0.0
deg_modifier = 1.0
if pace_cmd == 0: # Harvest
pace_modifier = 1.5
car["battery"] = min(1.0, car["battery"] + 0.25)
deg_modifier = 0.5
if car["status"] != "PIT": car["status"] = "HRV"
elif pace_cmd == 2: # Push
if car["override_unlocked"] and car["battery"] > 0.2:
pace_modifier = -1.2
car["battery"] -= 0.25
deg_modifier = 1.5
if car["status"] != "PIT": car["status"] = "OVR"
elif not car["override_unlocked"] and car["battery"] > 0.15:
pace_modifier = -0.6
car["battery"] -= 0.15
deg_modifier = 1.2
if car["status"] != "PIT": car["status"] = "BST"
else:
pace_modifier = 0.0 # Battery empty
else:
if car["status"] != "PIT": car["status"] = "STD"
# 3. Tyre Degradation & Noise
tyre_pace_deltas = {1: -1.0, 2: 0.0, 3: 1.0}
tyre_deg_rates = {1: 0.15, 2: 0.08, 3: 0.04}
compound = car["tyre_compound"]
deg_penalty = (car["tyre_age"] * tyre_deg_rates[compound]) ** 2
lap_noise = np.random.normal(0.0, 0.2)
# Apply final calculations
lap_time = base_lap_time + tyre_pace_deltas[compound] + deg_penalty + pace_modifier + lap_noise
car["last_lap_time"] = lap_time
car["total_race_time"] += lap_time
car["tyre_age"] += (1.0 * deg_modifier)
4. The Math of an Overtake
Because our simulation is lap-based, overtaking is probabilistic. If Car A’s total race time drops below Car B’s, an overtake attempt is triggered. The success of this battle depends on the 2026 Override mechanics, the age of their tyres, and the harsh reality of “dirty air.”
def _resolve_overtakes(self, grid_order):
"""Evaluates battles and applies time penalties for dirty air or successful passes."""
for i in range(1, len(grid_order)):
attacker = grid_order[i]
defender = grid_order[i-1]
# Did the attacker catch the defender this lap?
if attacker["total_race_time"] < defender["total_race_time"]:
overtake_chance = 0.3
# Modifier: Energy Modes
if attacker["status"] == "OVR": overtake_chance += 0.4
elif attacker["status"] == "BST": overtake_chance += 0.15
if defender["status"] in ["OVR", "BST"]: overtake_chance -= 0.3
# Modifier: Tyre Delta
tyre_delta = defender["tyre_age"] - attacker["tyre_age"]
overtake_chance += (tyre_delta * 0.05)
# Clamp probability
overtake_chance = max(0.05, min(0.95, overtake_chance))
if random.random() < overtake_chance:
# SUCCESS: Both lose 0.5s battling
attacker["total_race_time"] += 0.5
defender["total_race_time"] += 0.5
attacker["last_lap_time"] += 0.5
defender["last_lap_time"] += 0.5
else:
# FAILURE: Attacker gets stuck in dirty air
time_lost = (defender["total_race_time"] + 0.3) - attacker["total_race_time"]
attacker["total_race_time"] += time_lost
attacker["last_lap_time"] += time_lost
5. The Engine Orchestrator
We bundle these helper functions into our primary step() function, which acts as the beating heart of our Reinforcement Learning environment.
def step(self, actions):
"""Steps the environment forward by one lap."""
self.current_lap += 1
# 1. Snapshot the grid order BEFORE the lap starts
grid_order = list(self.cars)
# 2. Pre-calculate Override Eligibility (< 1s to the car ahead)
for i, car in enumerate(grid_order):
if i == 0:
car["override_unlocked"] = False
else:
gap_to_car_ahead = car["total_race_time"] - grid_order[i-1]["total_race_time"]
car["override_unlocked"] = (gap_to_car_ahead < 1.0)
# 3. Apply actions and calculate raw lap times
for car in self.cars:
team_action = actions[car["team"]]
self._process_car_lap(car, team_action)
# 4. Resolve Overtakes and Dirty Air
self._resolve_overtakes(grid_order)
# 5. Sort the field to get new track positions
self.cars.sort(key=lambda x: x["total_race_time"])
6. The UI: Rendering the Pit Wall Telemetry
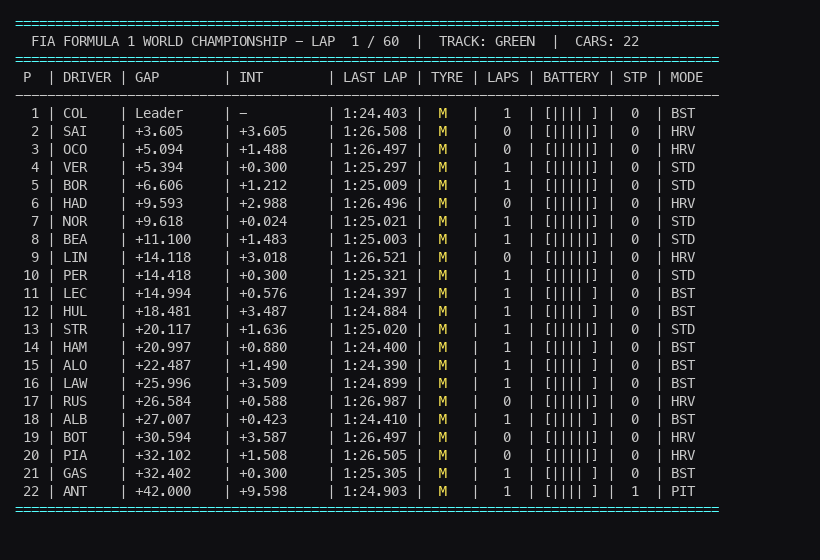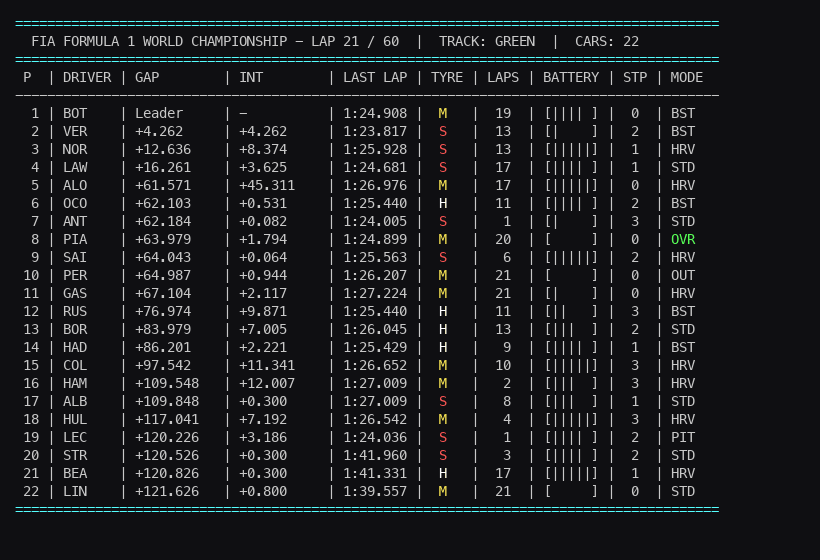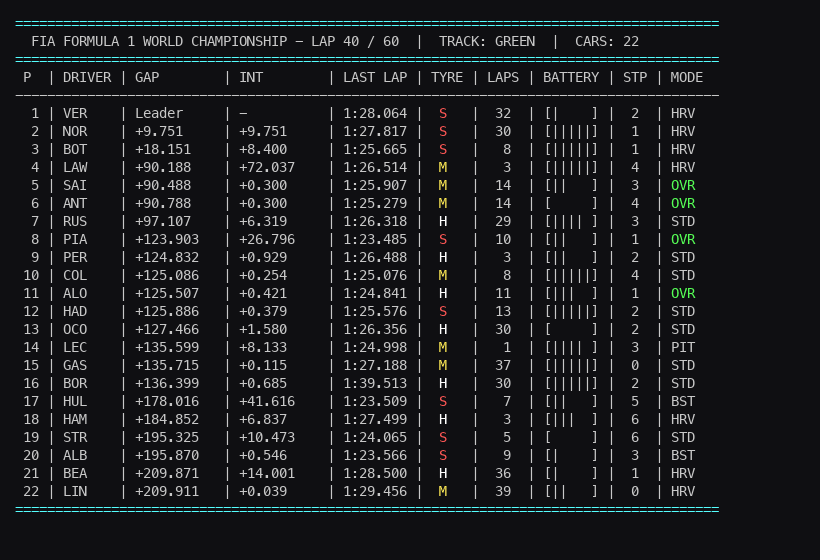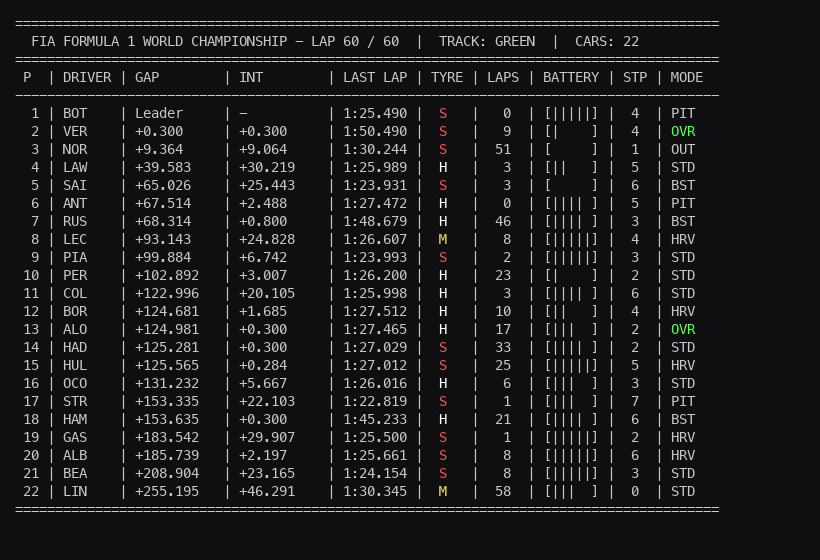
To train our AI, we need to see what it sees. Standard 2D animations aren’t very useful for F1 strategy. Instead, we render a highly dense, color-coded terminal interface that mimics an authentic F1 timing tower.
def format_time(self, seconds):
if seconds <= 0: return "0:00.000"
mins = int(seconds // 60)
secs = seconds % 60
return f"{mins}:{secs:06.3f}"
def render_telemetry(self):
# ANSI Colors
RED, YELLOW, WHITE, GREEN, CYAN, RESET = '\033[91m', '\033[93m', '\033[97m', '\033[92m', '\033[96m', '\033[0m'
os.system('cls' if os.name == 'nt' else 'clear')
leader_time = self.cars[0]["total_race_time"]
print(f"{CYAN}========================================================================================{RESET}")
print(f" FIA FORMULA 1 WORLD CHAMPIONSHIP - LAP {self.current_lap} / {self.total_laps} | TRACK: GREEN | CARS: 22")
print(f"{CYAN}========================================================================================{RESET}")
print(" P | DRIVER | GAP | INT | LAST LAP | TYRE | LAPS | ERS | STP | MODE")
print("----------------------------------------------------------------------------------------")
for i, car in enumerate(self.cars):
pos = f"{i+1:2d}"
driver = f"{car['id']:<6}"
if i == 0:
gap, interval = "Leader ", "- "
else:
gap = f"+{car['total_race_time'] - leader_time:<9.3f}"
interval = f"+{car['total_race_time'] - self.cars[i-1]['total_race_time']:<9.3f}"
tyre_str = f"{RED}S{RESET}" if car["tyre_compound"] == 1 else f"{YELLOW}M{RESET}" if car["tyre_compound"] == 2 else f"{WHITE}H{RESET}"
ers_blocks = int((car["battery"] / 1.0) * 5)
ers_bar = f"[{'|'*ers_blocks}{' '*(5-ers_blocks)}]"
status = f"{GREEN}{car['status']}{RESET}" if car['status'] == "OVR" else car['status']
row = f" {pos} | {driver} | {gap} | {interval} | {self.format_time(car['last_lap_time'])} | {tyre_str} | {int(car['tyre_age']):2d} | {ers_bar} | {car['pit_stops']} | {status}"
print(row)
7. Executing the Simulation (The Random Baseline)
Before plugging in a massive neural network, we must prove the environment works by running a “Random Game.” We loop through the laps, generating random pace and pit decisions for all 11 teams. We heavily weight the pit stop decision (85% chance to stay out) so the cars actually race instead of spending 50 laps in the pit lane!
if __name__ == "__main__":
env = F1TeamEnv(total_laps=25)
for race_number in range(1, 4): # Run 3 separate races to prove the random grid works!
print(f"\n--- STARTING RACE {race_number} ---")
env.reset()
time.sleep(2)
while env.current_lap < env.total_laps:
actions = {}
# Poll all 11 teams for their strategy this lap
for team in env.teams:
# Random Pace: 0=Harvest, 1=Maintain, 2=Push
pace1, pace2 = random.choice([0, 1, 2]), random.choice([0, 1, 2])
# Random Pit: 94% chance to stay out, 2% for Soft/Med/Hard
pit1 = np.random.choice([0, 1, 2, 3], p=[0.85, 0.05, 0.05, 0.05])
pit2 = np.random.choice([0, 1, 2, 3], p=[0.85, 0.05, 0.05, 0.05])
actions[team] = [pace1, pit1, pace2, pit2]
# Step the physics and render the board
env.step(actions)
env.render_telemetry()
# Pause to allow the user to watch the timing screen update
time.sleep(0.8)
print("🏁 CHEQUERED FLAG! 🏁")
time.sleep(3)
Next
By treating F1 as a sequential decision-making process, we’ve created a simple, game-theoretic representation of the 2026 regulations. We have state spaces dealing with imperfect information, an action space focused on long-term resource management, and a physics engine that rewards clever battery deployment.
Stay tuned for Part 2, where we strap this Python environment to a Proximal Policy Optimization (PPO) algorithm and teach our AI pit walls how to execute the perfect undercut!
[1] https://www.fia.com/sites/default/files/documents/fia_2025_formula_1_technical_regulations_-_issue_03_-_2025-04-07.pdf
[2] https://dl.acm.org/doi/10.1145/3672608.3707766